We previously outlined the basic protocol exchange for identity exchange for Thali here. But implementing this protocol requires dealing with a lot of details. The purpose of this specification is to capture those protocol issues. This is not intended as a proper protocol specification. It is makes a number of assumptions that are unique to our implementation environment. Eventually, for interoperability purposes, we will need to generalize this spec, but not today.
1 Protocol Messages
This section addresses the messages that are sent on the “wire” (in our case, actually BLE, Bluetooth and Wi-Fi) as part of the identity exchange protocol. This specification assumes the reader has read Thali’s coin flipping article, especially Appendix A.
1.1 Changes from the coin flipping article
In the abstract protocol the first step is exchanging public keys. In our case we will exchange public key hashes and because of how discovery works we get this exchange of public keys as part of the peer discovery process.
In the original article we used a serialization of the full public key for generating various values like cB. In this version we instead will use the hash of the public keys.
In the original article we specified that cB, hashA and hashB where generated with AES-CMAC. We are substituting SHA256 since it is equally strong and more readily available in Node.js (our primarily implementation platform).
We have some unfinished work to do to enable our Node.js platform to use TLS in the manner we require (see here). Until that work is completed we will instead include the claimed public key of each party in the requests and responses. Due to how the identity exchange protocol works this actually doesn’t break anything, even if peers lie.
1.2 The channel discovery and binding problem
Thali’s identity exchange protocol is specifically intended to be used over local P2P connections using technologies like BLE, Bluetooth and Wi-Fi Direct. In these environments there is typically a two step process in communicating with another peer. First, the peer has to be discovered. That is typically over a technology like BLE. Second, the peer has to be connected to over a high bandwidth connection, this usually involves Bluetooth or Wi-Fi.
An additional challenge is that in Thali’s implementation we assign a local TCP/IP port to a remote peer and then bridge from that local TCP/IP port to the remote peer over the local transport.
This enables all sorts of fun race conditions. For example:
Time A - TCP/IP Port P1 is assigned to peer Alpha
Time B - Peer A leaves and TCP/IP Port P1 is unassigned
Time C - TCP/IP Port P1 is assigned to peer Beta
If our local code queries for the port for peer Alpha at time A but didn’t use the port until time C then it would be talking over port P1 thinking its communicating to peer Alpha when in fact it is talking to peer Beta.
Our use of TLS prevents any unauthorized data transfers from happening but we still have to deal with the reality that binding problems can happen. This is accounted for in the state machine.
1.3 Discovery of potential peers to perform identity exchange with
Thali also has a temporary peer discovery mechanism where we advertise our public key hash over the local discovery channel (typically BLE). Eventually this mechanism will be replaced by the much more secure notification mechanism. But until we implement that mechanism we are taking a nasty little shortcut. The way that we advertise that a peer is available for identity exchange is by appending to their public key hash a “;” and then a 20 character or smaller “friendly name” that is intended to be shown to users. This replaces the first protocol exchange in the original article as now each party can discover the others public key next to the friendly name. Note that even if an attacker spoofs a message this can only cause a denial of service (the validations won’t match) it can’t actually caused the wrong key to be trusted.
1.4 POST to /identity/cb
Content-Type: application/json
Request-Body:
{
"cbValue": "base 64 string with cb",
"pkMine": "base 64 representation of the sender’s public key"
}
In the response we expect to receive a 200 OK containing a response body with:
Content-Type: application/json
Request-Body:
{
"rnOther": "The base 64 version of the receiver’s RNmine",
"pkOther": "The base 64 representation of receiver’s public key hash"
}
If the machine receiving the request either isn’t interested in doing an identity exchange or specifically doesn’t want to do an identity exchange with this peer then it will return a 400 Bad Request. The 400 response should contain a JSON error object of the form:
Content-Type: application/json
{
"errorCode": "some code",
"pkOther": "The base 64 representation of the peer’s hash"
}
| errorCode | Meaning |
| notDoingIdentityExchange | The peer is not attempting any identity exchanges or hasn’t selected a peer to do an identity exchange with |
| wrongPeer | The peer is trying to do an identity exchange but the requester isn’t the currently selected peer |
| malformed | Required fields are either missing or have unacceptable values |
| skippedAhead | A request was made to rnmine before a successful request to cb |
The inclusion of pkOther is a temporary expedient until TLS support is added. It is not part of the core security model and can only be abused to create a denial of service attack.
1.5 POST to /identity/rnmine
Content-Type: application/json
Request-Body:
{
"rnMine": "The base 64 version of the sender’s RNMine",
"pkMine": "base 64 representation of the sender’s public key hash"
}
We then expect back a 200 response containing:
Content-Type: application/json
Request-Body:
{
"pkOther": "The base 64 representation of the receiver’s public key hash"
}
At that point we can generate the 6 digit validation code.
The same 400 responses as described in the previous section also apply here with the addition of:
| errorCode | Meaning |
| skippedAhead | A request was made to rnmine before a successful request to cb |
2 State Engine model
The assumption here is that a peer has used discovery to see which other peers are available for identity exchange. The peer then picked the remote peer they wish to exchange with. As part of the discovery process the peer discovers the remote peer’s public key hash. The local peer then base64 decodes both hashes into binary buffers which are then turned into integers which are then compared.
2.1 A note on API assumptions
This section assumes that the state engine being described is called by someone who passes in a network identifier for the peer to communicate with along with the current peer’s public key hash and the remote peer’s public key hash.
There is presumed to be some mechanism whereby the state machine can bind the remote peer’s local ID with a local port to use to communicate to that peer. It is possible in some cases that when the local peer ID is passed in there might not yet be a port to communicate with that peer and in fact that port may never actually be obtained. If such a port isn’t known then the state machine has to wait until it gets an external notice informing it of the port associated with that peer ID. This rather odd approach is a side effect of the current Thali implementation where the identity exchange infrastructure can’t initiate connections to remote peers, another piece of code, called the replication manager, handles that. In a future Thali release this will change and the identity exchange code will be able to initiate connections.
The caller has the right to issue an “exit event” at any time which will cause the state engine to exit. The state engine is also assumed to have the ability to send messages back to the local caller, potentially multiple messages if necessary, to describe the outcome of the identity exchange process.
2.2 The local peer’s hash is smaller than the other peer’s
The following represents the state machine using PlantUML notation.
[*] --> GetPeerIdPort GetPeerIdPort --> MakeCbRequest : peer’s location is known GetPeerIdPort --> [*] : Exit Event MakeCbRequest --> GetPeerIdPort: Can’t connect to local port, 200 response with malformed content, wrong pkOther or otherwise unhandled HTTP error MakeCbRequest --> WaitForIdentityExchangeToStart : 400 + notDoingIdentityExchange, 404 Not Found or Lost Connection MakeCbRequest --> [*] : 400 + wrongPeer or Exit Event MakeCbRequest --> MakeRnMineRequest : Correct 200 response WaitForIdentityExchangeToStart --> MakeCbRequest : timer went off WaitForIdentityExchangeToStart --> [*] : Exit Event MakeRnMineRequest --> GetPeerIdPort : can’t connect to local port, 200 response with malformed content, wrong pkOther or otherwise unhandled HTTP error MakeRnMineRequest --> WaitForIdentityExchangeToStart : 400 + (notDoingIdentityExchange or skipped ahead), 404 Not Found or Lost Connection MakeRnMineRequest --> [*] : 400 + wrongPeer, Exit Event or correct 200 response to rnmine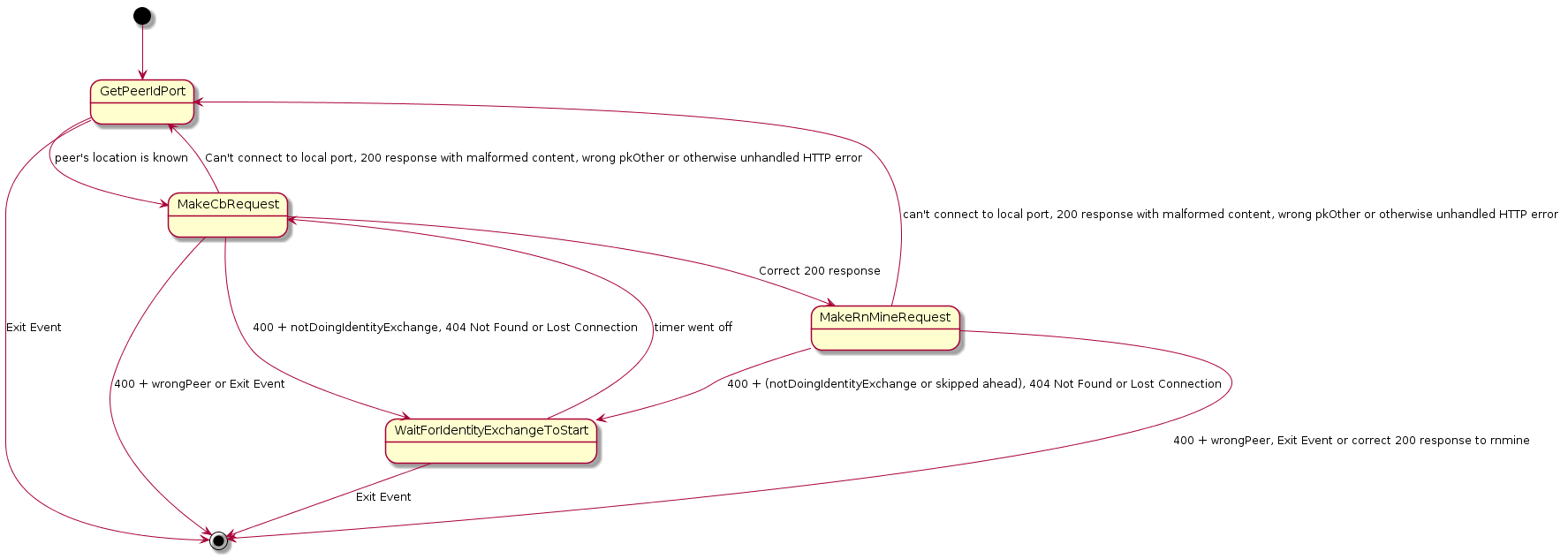
2.2.1 State: GetPeerIdPort
In this state we look to see if we can find a port for the peer we wish to communicate with. If the port is available then we connect. If the port is not available then we will wait until we receive an event notifying us that we now have a port for the desired peer.
Note that in cases where we arrive at this state after a channel binding problem we will have to detect if our list of ports has been updated since we last did a lookup on the desired peer. In other words if we looked up the port for client Alpha, tried to connect, realized we had a channel binding failure and come back to this state to try again we have to check to see if have received any updates. Note that it is theoretically possible to have the following scenario:
Time A - Port P1 is assigned to peer Alpha
Time B - Port P1 is lost
Time C - Port P1 is assigned to peer Beta
Time D - Port P1 is lost
Time E - Port P1 is assigned to peer Alpha
This means that our code could have gotten port P1 at time A thinking it was talking to peer Alpha. It connected at time C and figured out it was talking to Beta. So it comes back to this state to get an updated port for peer Alpha which could again be port P1. So we can’t just wait for the port assignment to change. We have to check if there have been any update notifications on the binding between peer and port.
2.2.2 State: MakeCbRequest
When we get to MakeCbRequest we will generate a new RNmine and a Cb value and make a request to /identity/cb. Keep in mind that the RNmine has to be a 128 bit random value and that when we generate Cb we will calculate it as SHA256(RNmine, PKmine || PKother). Which means we will take the RNmine raw binary buffer and use it as the key to SHA256 and then hash the concatenation of the raw buffers for PKmine and PKother in that order. That is, we are hashing the base64 decoded values.
| Result of /identity/cb Request | Next State |
| Can’t connect to local port or 200 Response with malformed content or wrong pkOther or unclaimed HTTP error | GetPeerIdPort |
| 400 + notDoingIdentityExchange or 404 Not Found or lost connection | WaitForIdentityExchangeToStart |
| 400 + wrongPeer or Exit Event | EndState |
| Correct 200 Response | MakeRnMineRequest |
If we can’t connect to the port then there is little to do but to wait for a new port to show up so we go to GetPeerIdPort.
If we get a 200 response with malformed content then we know we are dealing with someone who is either broken or trying to attack us. The best we can do is hope that we got connected to the wrong peer and so wait for a new port to show up. If one doesn’t then eventually whomever called us will time out. So again, we go to GetPeerIdPort.
Note that malformed content in this case means that:
- rnOther or pkOther is missing (it’s technically o.k. to have additional values)
- We can’t base64 decode rnOther or the decoded value isn’t the right size
- We can’t base64 decode pkOther or the decoded value isn’t the right size
If we get a 200 or 400 response with the wrong (but well formed) pkOther value then there are a few possibilities:
Attack This could be some weird kind of attack.
Buggy Peer The peer should have rejected the request and for some reason is not, we should just treat this as an attack.
Channel binding problem This is a fun little edge case. Imagine that peer A wants to do an identity exchange with peer B. Now imagine that at the same moment peer C wants to do an identity exchange with peer A. To complicate things further it turns out that the port that peer A has for peer B is actually now pointing at peer C (gotta love them race conditions). So peer A connects to a port that it thinks is for peer B but is actually for peer C. And peer C doesn’t think anything is wrong because it wanted to do an identity exchange with peer A. Oy.
This confusion between buggy peer and channel binding problem will eventually go away when we switch to TLS since the peer will have to authenticate themselves. But for now we can’t tell the difference and so will have to give the peer the benefit of the doubt and assume this is a channel binding problem. In that case we need to wait for a new channel and so go to GetPeerIdPort.
Another possibility is that we get some HTTP error code other than ones we explicitly handle somewhere else in this section. In that case we have to hope we have a channel binding problem because otherwise the peer is just broken. So again we wait for a new port by going to GetPeerIdPort.
If we get a 400 with a notDoingIdentityExchange and the right pkOther value then it means the peer isn’t ready to play yet. So the best we can do is retry by going to WaitForIdentityExchangeToStart.
If we get a 404 Not Found then we can’t tell if we have a channel binding problem or if the peer just isn’t ready to play. Eventually this situation will become clearer because TLS will remove the channel binding confusion. For now we will just assume the peer isn’t ready to play yet so we will go to WaitForIdentityExchangeToStart. Note that if there is a channel binding problem then WaitforIdentityExchangeToStart will eventually handle it since it switches to any new ports it finds when the timer runs out.
We could also get a connection prematurely closed (e.g. ECONNRESET) or otherwise lost. This isn’t necessarily a channel binding issue (although it probably is) so we have to assume we can just retry and go to WaitForIdentityExchangeToStart.
If we get 400 plus wrongPeer with the right pkOther than we have a peer who doesn’t want to play with us. At that point all we can do is return an error so that the person calling us can present UX to help the user understand what has happened and hopefully coax the person they want to exchange identities with to pick them instead of someone else. So we go to exit.
If we get an exit event then we exit.
And finally, if we actually get a 200 response with a proper rnOther and pkOther than its time to go to MakeRnMineRequest.
2.2.3 State: WaitForIdentityExchangeToStart
In general we get here because the peer isn’t ready to do an identity exchange yet. Right now there is a possibility that there could be a channel binding problem. Our main job is to set a timer and just wait until until the peer is ready. When the timer goes off we will try again with whatever port we last heard we were supposed to use for the peer.
2.2.4 State: MakeRnMineRequest
Here we just base64 rnMine and pkMine and send them off.
| Result of /identity/rnmine Request | Next State |
| Can’t connect to local port or 200 Response with malformed content or wrong pkOther or unclaimed HTTP error | GetPeerIdPort |
| 400 + (notDoingIdentityExchange or skippedAhead) or 404 Not Found or Lost Connection | WaitForIdentityExchangeToStart |
| 400 + wrongPeer or Exit Event | EndState |
| Correct 200 Response | Return verification code and go to EndState |
In general the potential outcomes for this state are handled in the same way as MakeCbRequest so please refer to that section for general guidance.
It’s tempting to argue that a wrong pkOther couldn’t possibly be a channel binding issue. But it turns out it can. There is no guarantee that the connection we use to make the rnmine request is the same connection we used to make the cb request and in the meantime the port could have been re-assigned. There are actually ways we could force the use of the same connection but life is short.
A new complication for a rnmine request is that we could get a skippedAhead error. Since we must have made a successful cb request to get to this state this means that the peer is bad, buggy or suffered a failure and restarted its end of the identity exchange process. We will give the peer the benefit of the doubt and go to WaitForIdentityExchangeToStart state to let us try again from scratch.
In theory we could handle lost connections differently than with MakeCbRequest. If we get a lost connection then we could just retry the rnmine request and get the 200 whose only purpose is just to tell us that the other side is done and is showing their user the validation code. But in this case it’s easier from an implementation perspective to just start everything over. One less thing to test.
If we manage to get all the way to a success in rnmine then we will generate the 6 digit validation code and return it to the caller.
When we reach the exit state all that means is that we won’t continue to try an identity exchange. But we also won’t do anything else until our global state machine’s state is changed. We basically just stop until told otherwise.
2.3 Our peer’s hash is larger than the other peer’s
[*] --> NoIdentityExchange NoIdentityExchange --> WaitForCb : Start with larger hash NoIdentityExchange --> WrongPeer : Start with smaller hash NoIdentityExchange --> [*] : Exit Event WrongPeer --> [*] : Exit Event WaitForCb --> WaitForRnMine : Received successful Cb request WaitForCb --> WaitForCb : Received failed Cb request WaitForCb --> [*] : Exit Event WaitForRnMine --> WaitForRnMine : Received a Cb or rnmine request WaitForRnMine --> [*] : Exit Event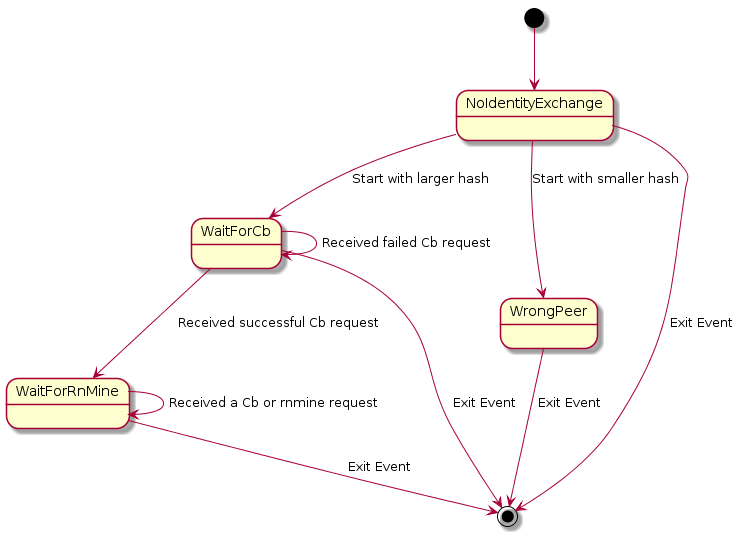
2.3.1 State: NoIdentityExchange
As a practical matter once we enter a mode to engage in an identity exchange we immediately start listening for requests to the two resources associated with identity exchange. Until we decide which peer we want to perform an identity exchange with we will stay in NoIdentityExchange state. And if the peer we end up picking has a larger hash than ours then we will stay in the NoIdentityExchange state for the duration of the identity exchange as we start up the other state machine defined above in parallel.
While in this state if we receive a request to either of the identity exchange resource addresses we will respond with a 400 Bad Request and the notDoingIdentityExchange error code.
The eventually chosen peer has a smaller hash than ours then we will go to WaitForCb. If they have a larger hash than ours then we will go to WrongPeer.
2.3.2 State: WrongPeer
If the peer we want to exchange identities with has a larger hash than we do then we know that we have to be the ones to contact them. Therefore anyone who contacts us is, by definition, the wrong peer. Therefore all requests to the two endpoints should be responded to with a 400 Bad Request and a wrongPeer error code.
2.3.3 State: WaitForCb
When we enter this state we know that we want to perform an identity exchange with someone whose hash is smaller than ours so we have to wait for them to send us a cb request. As soon as we receive the cb request we will check that the cbValue, when base64 decoded is of the right size. We will also check that the pkMine value, also when base64 decoded, matches the public key hash for the peer we wish to perform identity exchange with.
If either of the values is missing or malformed then we will return a 400 response with a malformed error code.
If the pkMine value doesn’t match the key hash for the peer we are looking for then we will return 400 with wrongPeer.
Otherwise if everything looks fine then we will generate a brand new RNmine value, record it and return it in the 200 response along with our public key hash. We will then go to WaitForRnMine state.
If we should receive a request to the rnmine endpoint then we will respond with a 400 bad request and a skippedAhead error code.
While we are in WaitForCb state we will serialize our handling of all incoming requests. We will also insert a one second wait before responding to any successful message. This is all intended to slow down any brute force attacks.
2.3.4 State: WaitForRnMine
In this state we have successfully received a cb request and generated our RNmine value. By having both our RNmine and the remote peer’s Cb value we have bound both of us to nonce values.
Ideally at this point we will receive a request to the rnmine endpoint.
When we receive a request to rnmine we perform the same sort of validation as discussed in the previous section. We check for required values, base64 decode them and make sure their sizes are right. If any of these checks fail then we respond with a 400 Bad Request and a malformed error code.
If we get a rnmine with the wrong pkMine value then we continue in our current state (e.g. with the recorded Cb and local RNmine values) and return a 400 with wrongPeer.
But if everything looks good we then return our public key hash in the response, generate the validation value and emit that to whomever called us and stay in the WaitForRnMine state. Typically we will remain in this state for some period of time after emitting the validation value in order to handle cases where the response might have been lost. In theory we could go back to WaitForCb since we know that our current design won’t have the other peer repeat a rnmine request (in case of failure it goes back to Cb) but it’s more robust to assume that the rnmine request could be repeated and so we allow for it.
If we should receive a cb request while in WaitForRnMine state then we must validate it as given in the previous section. If it fails validation (e.g. we aren’t responding with a 200) then we just return the appropriate error and stay in WaitForRnMine state.
If the request passes validation and has the same Cb value that we have already recorded then just return a normal 200 O.k. and stay in WaitForRnMine state.
If the request passes validation and has a new Cb value then before responding we must generate a new RNmine and return it in the cb response before again going back to WaitForRnMine state.
As noted previously we must serialize all requests and insert a one second wait before responding to any of the successful messages in order to slow down brute force attacks.
It is worth pointing out that it is possible for multiple validation values to be outputted by this process. This can happen if the remote peer gets all the way to making a successful rnmine request and fails before processing the response and then restarts everything from scratch (having lost its old rnMine value) and tries again. In that case when the client reaches rnMine state it will cause us to issue another validation value. This is obviously quite dangerous. Not just because it allows the attackers multiple opportunities to attack but because it causes the validation value to change in ways that could be visually confusing. As such users of this system are well advised to severely rate limit how often changes to the validation value will be accepted.
3 Security Considerations
3.1 Validating public keys vs public key hashes
In the original coin flip protocol we used serialized versions of entire public keys in the protocol. In this version we use the base64 decoded binary buffers of the public key hashes. In theory this should not matter. We hash the keys with SHA256 so collisions are not a concern. We are still resolving some issues about which exact keys we are moving around so we might revisit this decision later.
3.2 wrongPeer and data leakage
The wrongPeer error code obviously leaks information about who a peer wants to exchange identity information with. An attacker, for example, could try to listen to everyone announcing a willingness to perform identity discovery and try to emulate all of them to see who they get a wrongPeer for. However given that this protocol only runs over local radio the attacker would have to be physically present. If they are physically present then presumably they can observe who is exchanging identities. And by observation one does not necessarily mean through visual observation of the people involved. It’s also possible to observe the radio spectrum and see who is exchanging packets with whom. So the belief is that this error code does not add any additional security issues.
3.3 The effect of not supporting TLS on security
I strongly suspect that it doesn’t matter since the coin flip protocol was actually designed to be run in the clear. However we will be adding full TLS support before we do a real release so it just doesn’t matter.
3.4 Mitigating attacks on the coin flip protocol
The coin flip protocol can be defeated. For example, imagine we have Alice, Bob and Eve. Eve has successfully launched a man in the middle attack such that Alice is talking to Eve but thinks she is talking to Bob and Bob is talking to Eve but thinks he is talking to Alice. In this case Eve’s goal is to convince Alice that PKeve belongs to Bob and to convince Bob that PKeve belongs to Alice.
The simplest way to launch this attack is for Eve to get all the way to a rnmine request with say Alice and then hold for a second. Meanwhile she would take the validation code generated with Alice and try to get some value for her RNmine to induce the same 6 digit validation code with Bob. If Bob could, for example, be fooled into re-using a nonce (say as part of retrying a failed request) then Eve would only need to generate a million or so possible RNmine values to find one that will generate the same 6 digit validation code with Bob as with the one generated with Alice.
Of course that is why the nonce is called a nonce, as in, once. And hence we never re-use a nonce, even in failure scenarios. But we do have to define what we mean by “re-use” a nonce. The point of a coin flip or “commitment” protocol, that word commitment is key, is that re-using a nonce only occurs if both sides are allowed to pick new nonces. If we have completed the cb request then its fine to accept an unlimited number of rnmine requests because the cb request effectively binds both party to their nonces. The attack only works if Bob sticks with his nonce but Eve is allowed to change hers. That is the kind of re-use we prevent. Any time we respond successfully to a cb request it will be with a new nonce value. And any time we make a cb request it will be with a new nonce value.
But even constantly changing the nonces doesn’t prevent all attacks. Remember that even in the case that Eve gets one chance to launch her attack she still has a 1:1,000,000 probability of success just due to dumb luck.
But Eve can up her chances if she can start over the entire identity exchange process with Bob and keep retrying until she finally gets a matching 6 digit validation code. In this case both Bob and Eve are changing their nonces on each request (Eve can actually keep re-using the same nonce, but that doesn’t change anything). So Eve can’t predict when she will be successful but if she can get in enough requests then eventually she will succeed just through dumb luck.
To prevent this attack we intentionally serialize all requests we handle for the cb and rnmine endpoints and we put in a second delay on each successful response. This reduces Eve’s attack opportunities to no more than 60 per second. If Eve wants a 10% chance of success then she should need to run roughly 100,000 requests which would take 27 minutes. So the morale of the story is that identity exchange shouldn’t be left running for terribly long. Alternatively we could eventually just put in a hard limit to how many times we allow Cb to be reset before we give up or we can use the usual fall back of exponential back off. I suspect a time limit by whomever started the state machine is probably the simplest and most reasonable approach.
3.5 What about denial of service attacks?
There are so many ways to block local radios that we assume that DOS attacks will always work. Our only requirement is that a DOS attack cannot be allowed to force us into a “bad state”. But if someone doesn’t want anyone locally to use radios there is pretty much no way to stop them.