OAuth's current access dance is based getting a request token that is later exchanged for an access token. Introducing the request token takes what could have been a 4 round trip protocol and makes it into a 6 round trip protocol. Couldn't we just simplify OAuth down to 4 round trips by getting rid of the request token all together? Or is there some critical use case enabled by request tokens that makes all the complexity worth the price?
[5/26/2009 – Updated with Q&A on open redirectors]
[6/2/2009 – Updated with a note from Allen Tom on another way to prevent open redirector attacks]
To set the stage for the conversation it's useful to first review the newly proposed three legged OAuth message exchange pattern. The picture below is based on OAuth Core 1.0 Rev A (Draft 3):
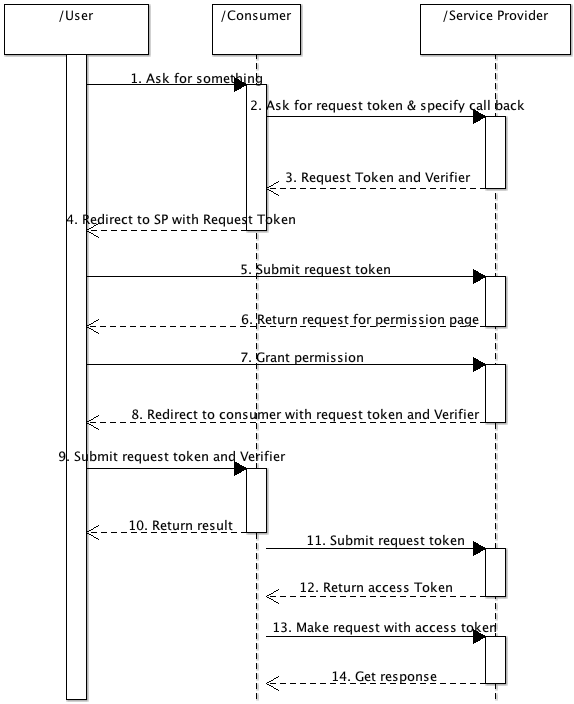
There are several things that concern me about the current OAuth pattern:
State – This pattern forces both the consumer and service provider to store someone else's state for a potentially non-trivial period of time. That is always a messy proposition at best. The service provider is forced to associate a call back with a request token and the consumer is forced to associate a verifier with a request token.
Performance – The service provider better implement messages 2/3 really quickly because the user is going to have to swallow all the latency of messages 1-4 before anything useful happens.
Complexity – Having 2 extra round trips means extra code, extra testing and extra chances for things to go wrong.
What if we instead use a pattern like:
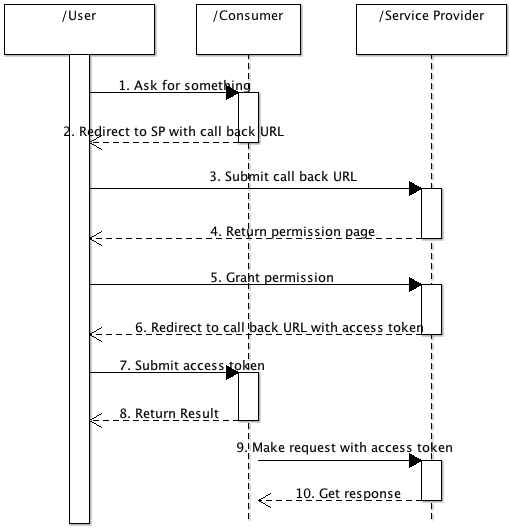
Now the only long term secret is the access token and only the consumer has to record it. The request/response pairs go down to four and the performance issue with requesting the request token is gone.
I suspect there is a good reason that OAuth felt it had to have the request token but I honestly am not clear what that reason is and if its important enough to justify the complications it introduces. Hopefully the article will set me on the path to finding out.
Q&A
Isn't the newly proposed pattern susceptible to phishing?
Absolutely. The short answer is that the consumer will need to associate a value with the callback URL that lets the consumer make sure that the user coming back on the call back URL with an authorization token is the same user the consumer sent out. This can be trivially handled via random numbers or encrypted ID. See below for details.
The attack is that a black hat user gets to message 2 (the redirect) in the previous chart and then doesn't actually execute the redirect but instead takes the call back URL and publishes it on a web page. The black hat convinces a white hat user to click on the link in a context where the white hat user expects to grant permission to the service provider. The white hat user grants permission and is redirected back to the call back URL specified by the consumer originally for the black hat user with the access token.
In theory the attack would be if the consumer somehow got confused and thought that the access token returned by the white hat user belonged to the black hat instead because the callback URL that was used was the one that the consumer had originally issued to the black hat.
It might seem trivial to prevent this attack – don't put any user identifying information into the callback. This means that when the callback arrives (e.g. message 7 in the picture above) the consumer will validate who the user is by whatever login method (if any) is being used and not via any values in the callback URL. This prevents the phishing attack from working.
Unfortunately this approach also makes an even more insidious attack possible. Let's assume the consumer doesn't put any identifying information into its callback URL. Let's further assume that the black hat goes through the entire permissioning process but swallows message 6, this is the redirect with the access token.
Let's further assume that the black hat fools the white hat into clicking on a link that sends the black hat's access token to the service provider. Assuming the white hat is logged in the black hat will think the access token belongs to the white hat user instead of to the black hat (remember, the redirect URL has no user identifying information so there is no way for the consumer to know who the token was issued for). Now when the consumer wants to interact with the service provider on behalf of the white hat they will actually use the black hat's access token.
To see how bad this could be imagine that the consumer is a service like Plaxo that handles address book synchronization and the service provider is some service with an address book like Live. In that case when the consumer wants to synch the white hat's address book with Live they will actually push all the address book information into the account the black hat set up and got the access token for. So much for the white hat user's private address book information.
To prevent this the consumer has to be able to associate an access token from the service provider with the user that the consumer had sent to get the access token in the first place.
There are a couple of ways the attack can be prevented. Probably the easiest is for the consumer to generate a cryptographically secure random number (can you say – verifier?) and stick it as a cookie on the user's browser and then stick that number into the callback URL. When the callback arrives the consumer compares the ID in the cookie with the ID in the callback and if they don't match then the access token is rejected.
If cookies aren't available (and that situation is getting increasingly less interesting) then the consumer can take the user's ID (this only works if the user has authenticated to the consumer) and encrypt it and put it on the callback URL. Then when the call back comes in the consumer checks the encrypted ID with the currently user ID and if they don't match rejects the request.
It is also possible to make things work in the case that the user is anonymous to the consumer and doesn't support cookies but that will require the user to manually copy and paste the authentication token back to the consumer.
Can't someone falsely pretend to be a consumer?
Sort of, but it won't help them.
The attack is that a black hat sets up a phishing site called blackhat.contoso.com that looks like whitehat.example.com. blackhat.contoso.com then fools a user into thinking its whitehat.example.com and redirects the user over to the service provider. What happens next depends on the relationship between the service provider and its consumers.
Let's take the most open case, the service provider allows a consumer to ask for user permission without requiring pre-registration. I actually was the PM on a project that shipped a system like this for Live and it worked fine. In that case the service provider will need to prominently display the consumer's DNS name from the callback to the user. So the user will see 'blackhat.contoso.com' and they thought they were coming from 'whitehat.example.com' and so the user will know to reject the request.
But let's say the blackhat gets fancy and instead makes the DNS in the redirect URL point to whitehat.example.com? In that case the user will do what they intended to do, give permission to whitehat, and the access token will be sent to whitehat's domain as part of the redirect. So blackhat got nothing for their efforts (other than maybe a thank you from whitehat).
Isn't this design susceptible to open redirector attacks?
The short answer is – yes.
The attack goes like this. Evil.com phishes the user into thinking that evil.com is actually stupid.com. Evil.com, in message 3 in the second picture above, then redirects the user to the service provider with a callback URL of the form: http://stupid.com/redirector?redirect=http://evil.com/dobadstuff.
As I pointed out in the previous question this attack is generally useless because the response will go to stupid.com, not evil.com. Unless, of course, stupid.com is criminally stupid. In which case the previous URL points to what's known as an open redirector. This is a web page on stupid.com's domain that accepts a URL as a query argument and will blindly redirect the user to that URL regardless of where it is.
There are at least two ways to secure the protocol as described above against open redirector attacks.
Require SSL callback URLs – Generally speaking open redirectors don't run over SSL so if the SP requires SSL callback URLs then the SP will have protected its users against most (but certainly not all) incompetent websites.
Require an out of band secret – The core of the attack is that evil.com, thanks to the open redirector, gets a copy of the authorization token which is what is known as a 'bearer token'. That is, mere possession of the token is proof that one has the right to use the token. So another fix is to require that the authorization token cannot be used on its own. Instead the SP and the consumer have to provision a shared secret out of band. In the simplest possible case (for the consumer) message 9 in the second picture requires that the shared secret be included on the request. Because evil.com won't have the secret that was provisioned for stupid.com any attempt to use the authentication token will fail. An alternative approach (this is preferable from a security perspective) is to sign the redirect in message 3 with the shared secret.
Perform Discovery – (Thanks to Allen Tom for pointing this one out) The SP can require that consumers provide a way to discover what addresses a consumer uses for callbacks. For example, the consumer, in message 3, could pass in a URL that points to the same domain as the callback URL. The SP would then do a GET on the passed in URL and get back a file that lists the callback locations the consumer supports. Obviously the SP wouldn't support redirects on that GET. Equally presumably the consumer wouldn't list in that location evil.com's address. So in theory that's that.
This all having been said I do not believe we should do anything about open redirectors. There are good reasons to want to run redirectors but it's been known for many years now that without canaries or some other form of protection these redirectors are very insecure. Running an open redirector without cross site attack protections is outrageously irresponsible. And I just don't believe we should design protocols against outrageously irresponsible behavior because no protocol can be protected against all the idiotic things an irresponsible person can do.
And, for what it's worth, Live's first delegated authentication system worked exactly as this blog post describes. You can see an overview here. And yes, we were fully aware of the open redirector problem and no, we didn't try to protect against it for exactly the reasons described in this Q&A.