The Enterprise SOA vision is all about composite applications. These are applications formed out of numerous independent web services all working together to provide some greater functionality. Except, how exactly do you define how 20 or 30 loosely coupled services interact to form a composite application? How do you deploy 20 or 30 services written in 20 or 30 languages for 20 or 30 different platforms in a sane way? And if you do manage to actually design and deploy the beast, how do you monitor it? The tools needed to make SOA work in the real world mostly don't exist yet. That's o.k. though because most Enterprises are just taking their first baby steps down the road to SOA. So we have a little time to get our act together. This article lays out a vision for how an architecture that will allow enterprises to maximize SOA's benefits.
SOA Lifecycle (SOAL)
Today designing and managing a complicated composite application is nearly impossible. There are simply too many parts. Trying to design a non-trivial composite application using white boards and documents is just too limited and brittle. Trying to deploy a composite application that could easily be made up of 20 or more services is fiddly at best and trying to figure out how to monitor and manage such a beast is proving to be an enormously expensive task.
The SOAL approach is all about making it economical to take advantage of composite applications. The core of the SOAL approach is the idea that one needs a consistent model of the composite application's choreography, composition, configurations, etc. that is maintained through all stages of the SOA lifecycle – Design, Development, Staging, Deployment and Management. Or, just to be politically correct:

Hopefully that spaghetti of connections will satisfy just about every possible iterative design strategy known to humanity. But in any case, the key is to have models that are consistent and maintained throughout all stages of the life cycle. Below I discuss the two artifacts that make this possible, the choreography description and the map. I will then discuss the composite application manager, the provisioning service and the monitoring service who work together to turn a choreography and map into a running, manageable, composite application.
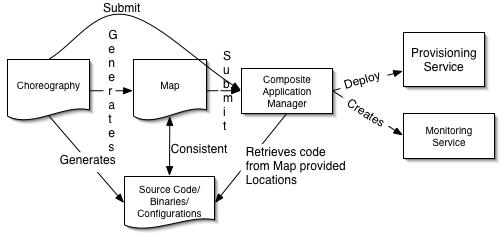
Design: Choreography
To build a composite application one has to first design it. This is where choreography comes into the picture. A choreography specifies which services will communicate with which other services using what messages and in what order. The choreography doesn't say a whole lot about how the services work or how they decide what to do next, it just lays out the message flow. The example below shows a simple choreography for a travel agent scenario.
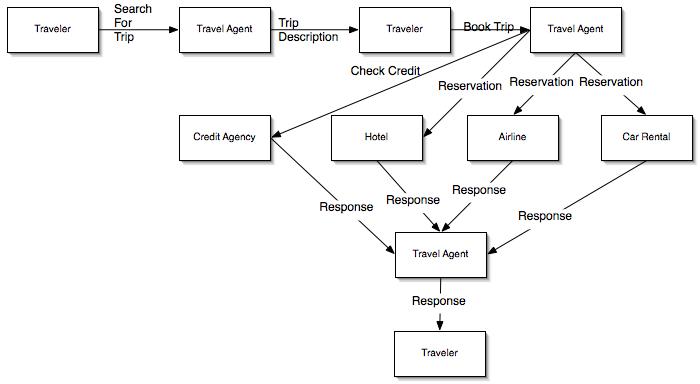
The purpose of the choreography is to allow the composite application architect to describe, at a high level, what a composite application will do and roughly how it will do it. See my article on WS-CDL for more details on what makes for a good choreography description.
Development: Map
The choreography is powerful but it can also be overwhelming. When designing, deploying or managing a composite application one wants a simpler representation to work with. This is where the map comes in. The map displays all the services involved in a composite application along with links to identify who is talking to whom. What a map doesn't display is anything regarding message ordering.
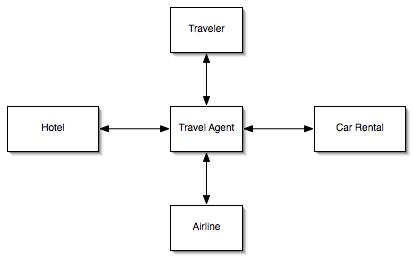
The map, however, is much more than just a simplified view of the choreography. The map is really a manifest that identifies what services the composite application is made up of and any information needed to develop and/or deploy the service. For services that are being developed locally the map will record pointers (URLs, file locations, etc.) to configuration files, source code, binaries, preferred editors to alter the above, etc. For services that already exist or being developed remotely the map will record URLs, configuration information needed to communicate with those services, etc.
During development time one would expect to see the map as the opening screen in a developers IDE with the developer then double clicking on services whose configuration or code need to be changed.
During test and deployment time however the map is responsible for even more information. For example, for any services being deployed locally the map would be responsible for specifying what resources (e.g. CPU, memory, disk space, database access, etc.) each service needs. In addition the links on the map would be annotated with service level agreement (SLA) information such as how many messages per second one expects the link to carry, although more imaginative SLA terms are also possible.
Development: Code Skeletons, Source Code, Configurations and Binaries
Generally speaking source code and binaries enter the SOAL infrastructure via the map. But the choreography has a role to play as well. It is possible to generate code skeletons based on the choreography. For example, the following is a pseudo-BPEL version of the Travel Agent process:
<process name="Travel Agent">
...
<receive partnerLink="traveler" portType="T:ravel" operation="Query".../>
...
<reply partnerLink="traveler" portType="T:ravel" operation="Query" .../>
...
<receive partnerLink="traveler" portType="T:ravel" operation="Book" .../>
...
<flow>
<invoke partnerLink="CreditAgency" portType="C:redit" operation="Check" .../>
<invoke partnerLink="Hotel" portType="H:otel" operation="Book" .../>
<invoke partnerLink="Airline" portType="A:irline" operation="Book" .../>
<invoke partnerLink="CarRental" portType="Car:rental" operation="Book" .../>
</flow>
...
<reply partnerLink="traveler" portType="T:ravel" operation="Book" .../>
</process>
One can easily imagine adapters that can read a particular service from a choreography and generate a code skeleton in the programmer's language of choice. But these skeletons are only a starting point and if the choreography is changed it is all but certain to be impossible to fix the code to comply with the new choreography. At best one can imagine a notification system telling the programmer that an update has happened. It is possible to create a coding environment that could automatically update code whenever the choreography is changed. But the limitations necessary to make such an environment work are draconian enough that it's unlikely the environment would be useful for anything but the simplest of services.
Most modern enterprise service design environments already contain numerous configuration files and newer environments have adopted a meta-data driven programming approach where service configuration information is annotated right on the source code. Since the map directly contains certain kinds of configuration information there is a possibility of conflict between the code and the map. In the end the code and its associated configuration files and binaries will win out so it is the job of the map to make sure it is consistent with the code. At a minimum tools will be needed to confirm that the map's configurations and the configuration contained in the actual code are consistent. But, one can reasonably expect that quite quickly IDEs will be developed that will make it possible to automatically keep in sink configuration files/source code and the map.
It is worth repeating that the map uses URLs, file share locations, etc. to point to source code, configuration files, binaries, etc. The map itself is really just a bunch of pointers with some configuration information. By keeping code/binaries/etc. separate from the map it becomes possible to use the map with whatever platforms or languages are desired for the mixture of services the map refers to.
Staging & Deployment: Composite Application Manager
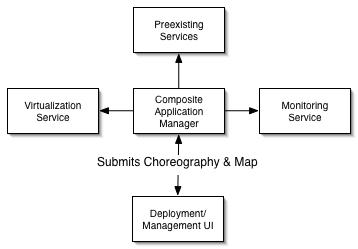 The composite application manager performs the bulk of the work of creating and managing a composite application. It begins its work by parsing the choreography and the map and determining if the submitted user is authorized to create the services and connections specified in the map as well as validating that the map and choreography follow system policies. If any problems are discovered the management service will communicate these back to the deployment UI.
The composite application manager performs the bulk of the work of creating and managing a composite application. It begins its work by parsing the choreography and the map and determining if the submitted user is authorized to create the services and connections specified in the map as well as validating that the map and choreography follow system policies. If any problems are discovered the management service will communicate these back to the deployment UI.
For services that need to be created from scratch the composite application manager will allocate resources. Most likely this resource creation step will occur via a virtualization service. The composite application manager will send a resource request to the appropriate virtualization service specifying CPU capacity, memory capacity, disk capacity, network bandwidth, OS, app server, etc. as well as provide the code of the actual application to be run. The virtualization service will then handle allocating the resources, configure them as indicated and bring up the application.
The composite application manager will also contact preexisting services that are used as part of the composite application and at a minimum make sure they are alive. Ideally however the composite application manager will be able to forward to the preexisting service a description of the expected resource requirements (in terms of type of messages as well as message throughput and latency requirements) so that the preexisting service can determine if it can handle those requirements (a determination which may include the service extending its own resources via its own composite application manager).
If any problems come up while deploying new services or contacting existing ones the composite application manager will contact the deployment UI and try to work with the user to resolve the issues.
The Composite Application Manager will complete the deployment process by creating monitoring services, described below, that will monitor if the SLAs specified in the map are being met at test/run time.
Management: Monitoring Service
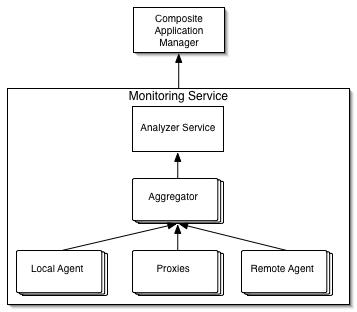 Managing distributed applications is typically an exercise in reverse engineering. The administrator has some general idea of how the application is supposed to work and then tries to stick monitors in enough places to confirm if the system is functioning as they expect. Thanks to the map, SOAL has a description of exactly what the composite application is supposed to look like along with SLA and other information to describe its expected behavior. This enables the composite application manager to create a monitoring service which can validate if the map's view of the world is correct.
Managing distributed applications is typically an exercise in reverse engineering. The administrator has some general idea of how the application is supposed to work and then tries to stick monitors in enough places to confirm if the system is functioning as they expect. Thanks to the map, SOAL has a description of exactly what the composite application is supposed to look like along with SLA and other information to describe its expected behavior. This enables the composite application manager to create a monitoring service which can validate if the map's view of the world is correct.
The monitoring service is itself a composite application. The first step in creating a monitoring service is to deploy agents/proxies that monitor the operational state of the services that make up the composite application. Each of the agents/proxies would be configured just to collect the data necessary to validate the SLAs and resource allocations specified in the map. Data from the agents/proxies would be forwarded to aggregator services who would compile the stream of updates into an intermediate form that would then be submitted to an analyzer service who would turn the aggregated data into final summaries that would detail how specific SLAs are or are not being met.
The combination of the monitoring service and the choreography is especially powerful as together they can validate if services are communicating in the order and to the services that the choreography calls for. Discovering inconsistencies between the choreography and runtime behavior is an especially powerful error detection and debugging tool.
Management: Composite Application Manager
Once the composite application is running any changes in its configuration, services, etc. will be made by changing the choreography and map and submitting those changes to the composite application manager who will then handle updating the existing composite application to the new configuration. Requiring all changes be made to the map and then versioning the new map against the old map held by the composite application manage ensures that the composite application manager always has an up to date description of the desired application behavior.
Of course, back in the real world, it's highly unlikely (to put it charitably) that all changes will end up going through the composite application manager. My best guess is that composite application managers will first be produced by platform vendors who will make sure that their components can be configured through the composite application manager. I further suspect there will be a good business in building (off the shelf or via toolkits) adapters for legacy systems that can interact with the legacy system's configuration/management interfaces to expose the services the composite application manager expects.
Conclusion
If I were to show this article to someone who was an expert in Product Lifecycle management (PLM) they would probably cough politely, look a little embarrassed for me and then point out that they have been doing the sort of things SOAL calls for for over 10 years now. I furthermore have no doubt that one could find academic articles calling for the sort of 'end to end' modeling that SOAL calls for going back at least 20 if not 30 or more years. And, of course, the MDA folks have been screaming their religion from the rooftops for years now. It all goes to show that there really is nothing new under the sun. So the question one has to ask about SOAL is not if it's right but rather if it's right now.
My belief, and the reason why I wrote this article, is that it's time for SOAL. As we watch our customers flounder trying to build more with less it's clear that we have to increase their productivity. It's equally clear that for all the enormous benefits SOA provides those benefits come with some very serious scaling problems that only a solution like SOAL can address. Until now, before networking became as unbelievably pervasive as it has today, it was possible to build monolithic and largely isolated software. To be fully truthful, most of our customers are still building monolithic and largely isolated software, the only difference is that the client terminal is connected via a protocol instead of a wire.
But new projects don't work like the old ones. The new projects we see are focused on distributed services that pull in functionality from multiple groups internally and even more groups externally. The financial pressure to increase productivity requires that software projects re-use rather than re-invent but we haven't armed software architects, developers and administrators with the tools they need in order to enable robust, distributed, mission critical process sharing. That's where SOAL comes in. It provides a framework for building the tools that are needed to deliver on the promise of SOA.
So SOAL, in one form or another, is going to happen. The real question is – how? What are the baby steps that will get us from here to there? That's a topic I look forward to addressing in future articles.